Если вы когда-нибудь поднимали self-hosted (on premise) версию Sentry, то знаете, что лезть туда очередной раз сильно не хочется: там ~38 контейнеров. Но иногда возникают нештатные ситуации.
Пару раз у меня случалось так, что какой-то сервис начинает сбоить и без конца отправлять в Sentry ошибки и евенты. Огромное количество ошибок (десятки и сотни тысяч). В такой ситуации я наблюдал два варианта развития событий:
-
Стремитально заканчивается место на диске:
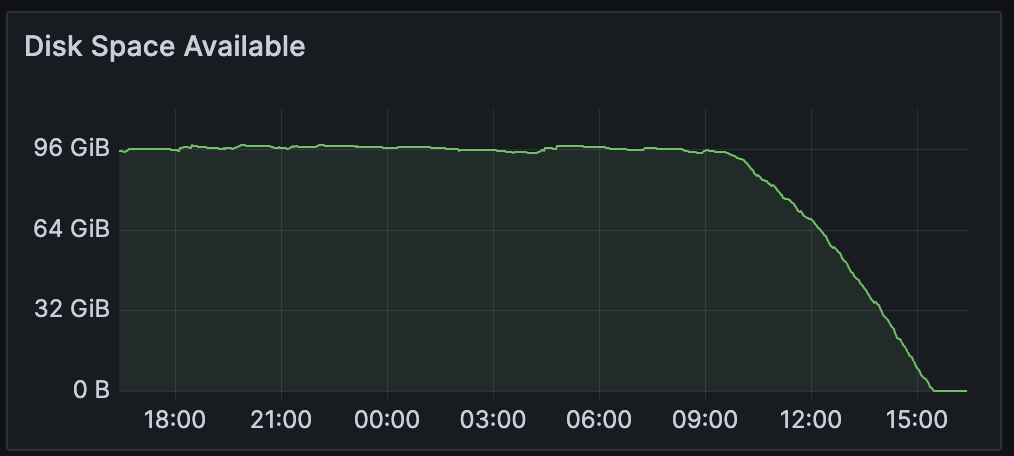
-
Запредельно возрастает нагрузка на оперативную память:
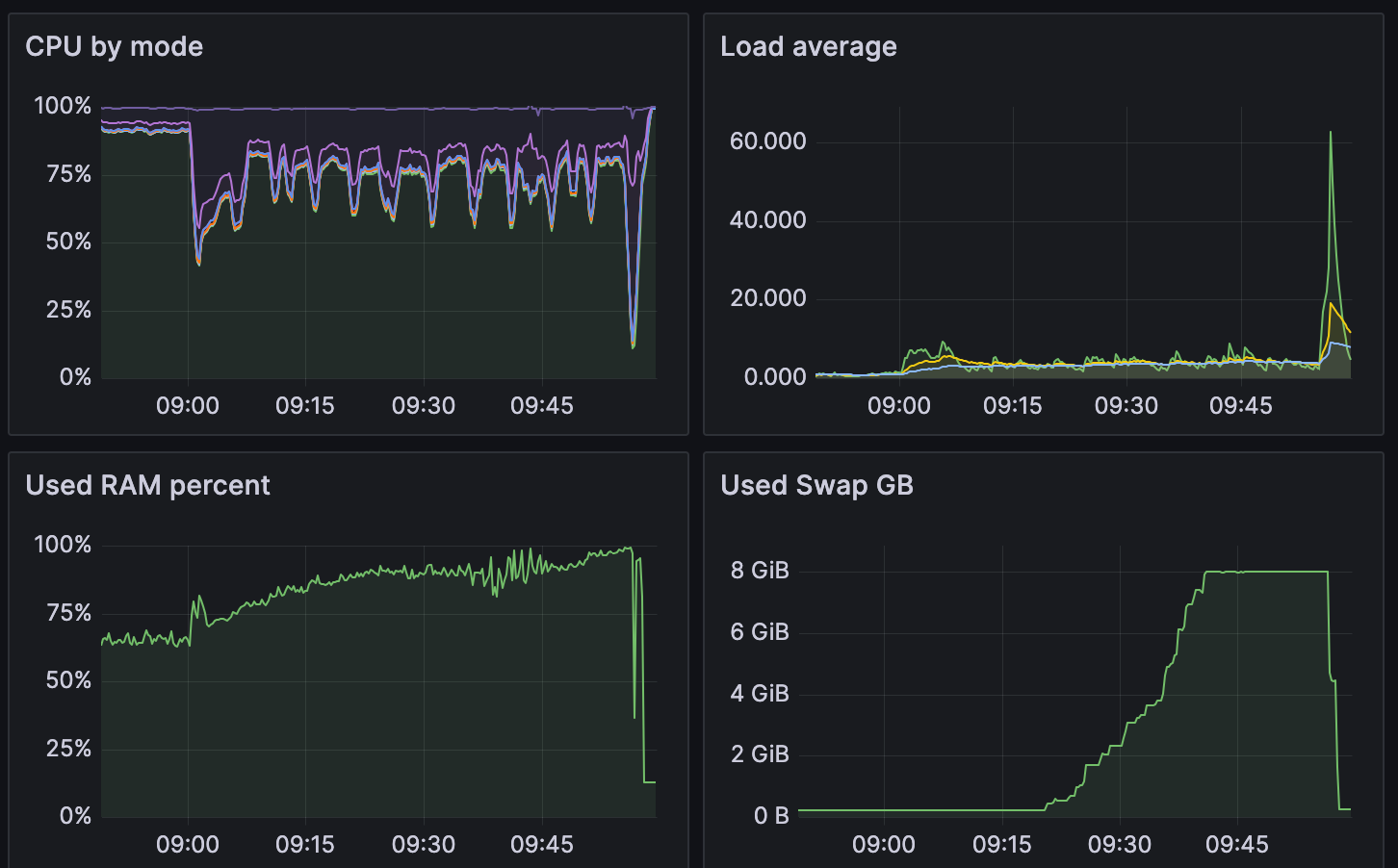
Закончилось место на диске #
Проверяем место на дисках, смотрим какие директории(вольюмы) больше всего жрут места:
du -Sh / | sort -rh | head -
Если в выводе на первых местах будут вольюмы sentry-kafka - значит двигаемся в верном направлении. Получается, что наши эвенты попали в Kafka, но еще не пошли дальше в сторону основной базы.
docker compose добавляю --env-file .env.custom, так как он используется для запуска моего инстанса Sentry.
Если вы перед этим выключили Sentry полностью, то сейчас стоит включить только Kafka:
docker compose --env-file .env.custom up -d kafka
Заходим внутрь контейнера с Kafka и смотрим размер топиков:
docker compose --env-file .env.custom exec -ti kafka bash
kafka-log-dirs --describe --bootstrap-server localhost:9092 --topic-list ingest-events
kafka-log-dirs --describe --bootstrap-server localhost:9092 --topic-list events
Чтобы освободить место занятое евентами, которые лежат в топиках, надо пойти немного хитрым способом: мы установим retention на очень маленькое значение (1 секунда), а потом вернем обратно.
# устанавливаем retention
kafka-configs --zookeeper zookeeper:2181 --entity-type topics --alter --entity-name ingest-events --add-config retention.ms=1000
kafka-configs --zookeeper zookeeper:2181 --entity-type topics --alter --entity-name events --add-config retention.ms=1000
# ждем пока освободится место (1-10 минут)
# откатываем назад
kafka-configs --zookeeper zookeeper:2181 --entity-type topics --alter --entity-nameingest-events--delete-config retention.ms
kafka-configs --zookeeper zookeeper:2181 --entity-type topics --alter --entity-nameevents--delete-config retention.ms
Теперь нужно сбросить offset-ы в топиках:
kafka-consumer-groups --bootstrap-server kafka:9092 \
--group snuba-consumers --topic ingest-events \
--reset-offsets --to-latest --execute
kafka-consumer-groups --bootstrap-server kafka:9092 \
--group ingest-consumer --topic ingest-events \
--reset-offsets --to-latest --execute
kafka-consumer-groups --bootstrap-server kafka:9092 \
--group post-process-forwarder --topic events \
--reset-offsets --to-latest --execute
На этом вроде всё.
Забита вся оперативная память #
Это ситуация, когда евенты прошли дальше Kafka, уже в Redis. Это видно по тому, что, собственно, Redis начинает использовать очень много оперативки. Можно посмотреть через htop, docker stats или ctop.
Проблема в том, что Redis - это in-memory хранилище, и если значений становится очень много, они перестают умещаться в память, а дальше цепная реакция приводящая к приходу OOM-Killer.
Здесь решение комплексное:
# идем в контейнер с Redis
docker compose --env-file .env.custom exec -ti redis sh
# смотрим какой сейчас eviction policy настроен
redis-cli info | grep maxmemory_policy
# скорее всего там стоит noeviction, что значит, что Redis будет использовать всю доступную оперативку, а потом перестанет обрабатывать новые запросы
# поменяем тип политики, и установим лимит maxmemory, на что-то разумное
redis-cli CONFIG SETmaxmemory-policy volatile-ttl
redis-cli CONFIG SETmaxmemory 7G
Добавляем конфиг-файл для Redis #
Создаем директорию и файл для конфига:
mkdir redis
nano redis/redis.conf
# туда вставляем настройки
maxmemory 7G
maxmemory-policy volatile-ttl
Теперь надо этот файл подмонтировать в контейнер с Redis. Сделаем это через создание override файла nano docker-compose.override.yml:
services:
redis:
command: ["redis-server", "/usr/local/etc/redis/redis.conf"]
volumes:
- ./redis/redis.conf:/usr/local/etc/redis/redis.conf
Теперь перезапускаем Redis и проверяем, что настройки подцепились. Можно через docker inspect, но еще лучше будет зайти внутри контейнера и поgrep-ать их из redis-cli info.
Я еще делал redis-cli flushall чтобы очистить весь кэш и освободить память.
После всех процедур обязательно проверяйте, что контейнеры запущены и не рестартуются, что новые эвенты прилетают.
Траблшутинг Kafka после очистки топиков #
После всех этих процедур эпопея с Kafka не закончилась. Некоторые consumers со временем начинали вылетать с ошибками в логе:
arroyo.errors.OffsetOutOfRange: KafkaError{code=_AUTO_OFFSET_RESET,val=-140,str="fetch failed due to requested offset not available on the broker: Broker: Offset out of range (broker 1001)"}
Как бы в этой ситуации надо остановить consumer-ы, сбросить значение оффсетов как мы делали выше, запуститься обратно. Но мне не помогло. Пошел другим путем и начал удалять группы полностью:
kafka-consumer-groups --bootstrap-server kafka:9092 --delete --group ingest-consumer
kafka-consumer-groups --bootstrap-server kafka:9092 --delete --group snuba-consumers
kafka-consumer-groups --bootstrap-server kafka:9092 --delete --group post-process-forwarder
kafka-consumer-groups --bootstrap-server kafka:9092 --delete --group post-process-forwarder-errors
kafka-consumer-groups --bootstrap-server kafka:9092 --delete --group post-process-forwarder-transactions
Тоже не помогло, через некоторое время консюмеры начали рестартиться.
Более мощный способ - это грохнуть volume kafka и zookeeper полностью через docker volume rm.
docker compose --env-file .env.custom down
docker volume rm sentry-kafka sentry-zookeeper
docker volume rm ah_sentry_sentry-kafka-log ah_sentry_sentry-zookeeper-log
После этого надо создавать топики заново, и в моем случае самым простым способом оказалось прогнать ./install.sh скрипт заново. Он учитывает наличие .env.custom, не трогает Postgres и в целом очень мягко бутстрапит заново все что нужно.
Reference: часть гайда взята из статьи Юрия на Medium. Спасибо ему большое. Статья уже не раз мне помогала.